03
OPENCLAW CONSOLE
后来我把“小德”升级成可运营的中控台
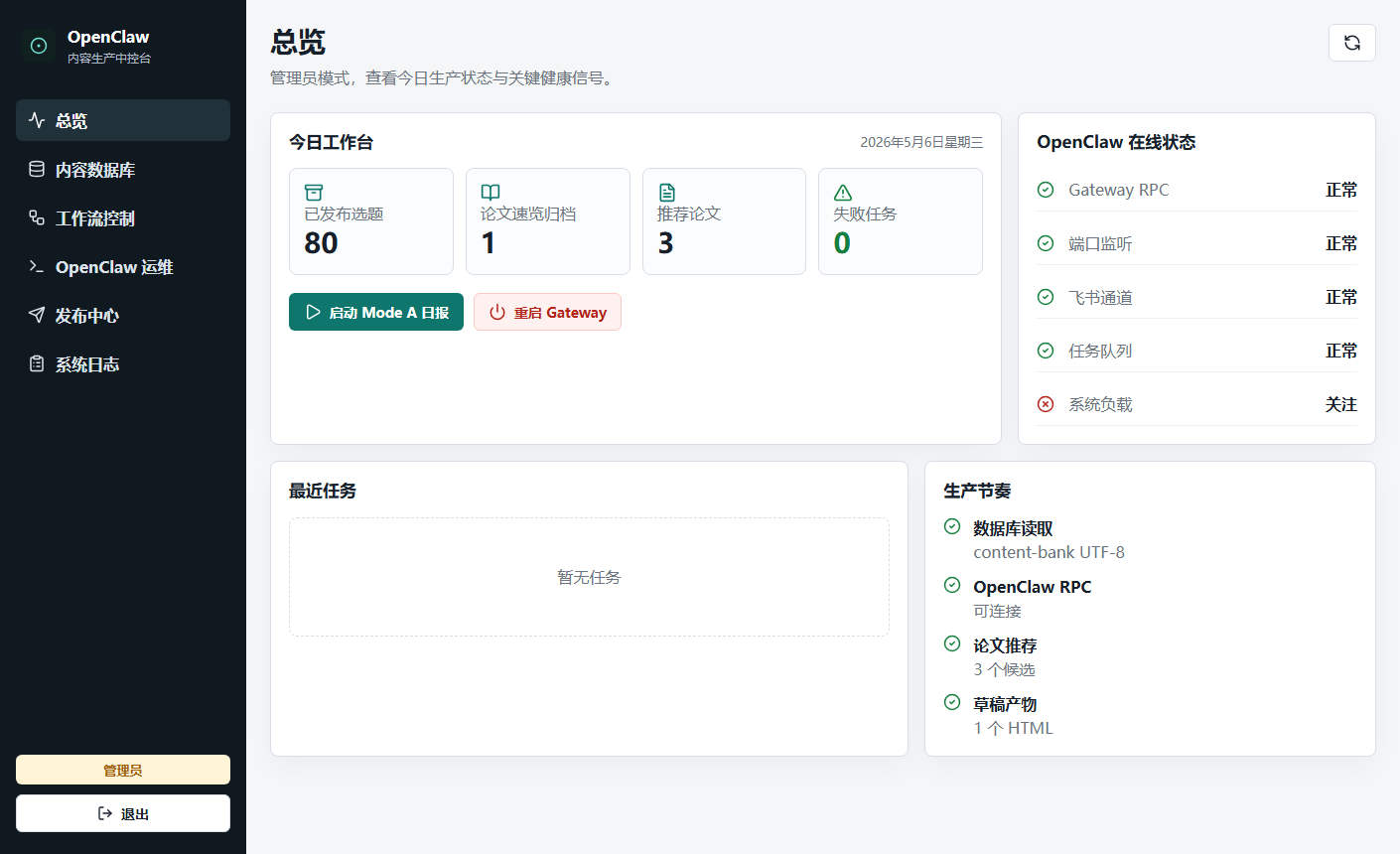
第一阶段解决的是“能不能自动生成一篇公众号文章”。真正上线后,问题变成了另一组更像产品和运维的问题: 今天跑到哪一步了?候选在哪里选?哪篇论文可以进 Mode B?OpenClaw 网关是不是活着?备用通知有没有发出? 失败任务怎么重试,产物保存在哪里,数据库字段缺失怎么修?
所以我做了一个本地 React + Express 中控台,把内容生产链路从“命令行 + 文件夹状态 + 分散消息”收束成一个老板和管理员都能用的后台。 它让小德从一个会写稿的 agent,变成一套能被人监督、审批、排障和持续运行的业务系统。
Mode A/B 工作流控制99% 操作在这里完成:启动日报、批准论文速览、查看候选列表、提交选题并追踪写稿阶段。
内容数据库治理已发库、备选池、论文池统一检索,支持查重、字段修复、SQLite/JSON 同步。
OpenClaw 运维面板检查 Gateway、RPC、通知通道、任务状态和网络访问入口,必要时触发重启。
失败任务自修复识别假运行、日期错乱、HTML 产物缺失和发布失败,把修复入口留在任务表内。